The True Art of Data Archaeology – Overdrive

My friend Sailor/Triad at http://blog.worldofjani.com and I were speaking about how to take a deeper step into the tapes I had recived and preserved. We both felt we were far from done with this task!
This is his overdrive of the "sicherheitskopien Spiele II" tapes - Read and enjoy.
prewords:
My friend Xiny6581 at the http://sidpreservation.6581.org/ asked me to take a deeper dive into a tape he had gotten for preservation. You can read his findings on the tape at:The True Art of Data Archaeology, but we both felt there was more to find out on these tapes.
We came pretty quick to the conclusion the tapes were disk backups saved to a turbotape format. None of the current turbo transfer tools were able to identify the files, nor the format properly.
I made a tool to inspect the raw turbo-data on the tape. The files start with a standard turbo-tape header and the rest of the data is custom turbo-tape. With this information i made a tool which saved the raw data to disk.
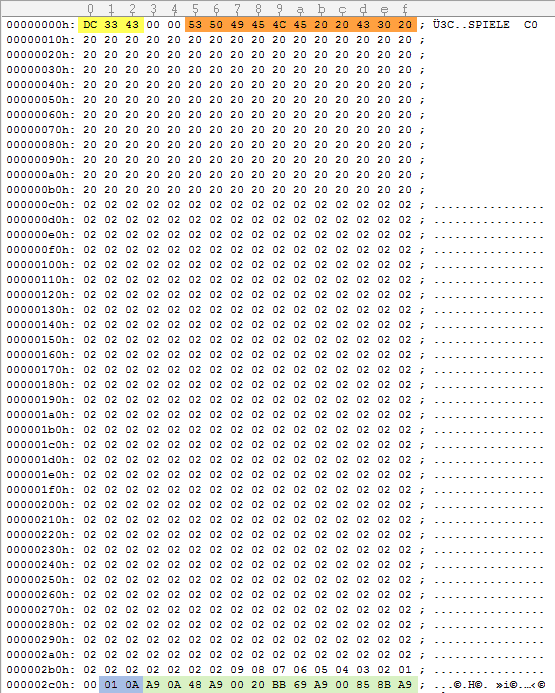
After the turbo-tape header, a custom header follows with $02a1 bytes of data. The header has checksum(Yellow) and a name(Orange). The name is something you’d type in since it does not reflect the name of the disk. When restoring, the original program probably looked for “a bunch” of $02;s plus a sequence of $09,$08…$01,$00 and everything after those bytes is data.
Four consecutive files on the tape has the same name in the custom header why I came to the conclusion each disk was split into four files.
I was able to determine the size of the header by assuming the first block of data from the tape was from the lower tracks(sectors) of the disk. Therefor the bytes $01,$0a is a track/sector-link(lightblue) and the bytes $a9,$0a,$48,$a9,$00, which translates to LDA #$0A/PHA/LDA#$00, is programdata(lightgreen). This is how the data is structured on a disk.
Now i had found an offset for the disk data. I knew every $0100 bytes after the header corresponds to a sector on the disk. However, this was the easy part. I got pretty fast aware of the fact the sectors were in no logical order. After saving all data out, I had 9 backups of disks giving a total of 683*9(=6147) sectors that had to be puzzled together.
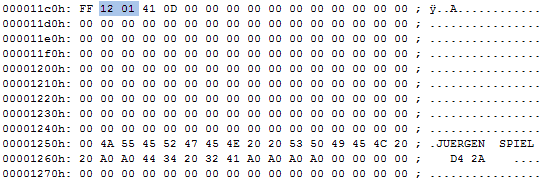
I started reconstructing the directory tracks. Track 18.0 holds the disk name and was found on all backups in the third file at position 0x11c1. It will also link to track 18.01 (hex $12,$01) which is the first block with filenames and track/sector links to the files.
One of the games was Flight Simulator II. Knowing that it is a full disk copy with the same placement of sectors(data) throughout the disk compared to the original game caught my interest. I made a tool which checksummed every block of $0100 bytes from the four files and compared it to every sector on the original disk. When there was a match, I knew which memorypositon in which file corresponded to a track/sector on the disk. After a match, the tool would not check the same sector twice.
I got out a fair amount of matches, not all though, since many sectors were empty and therefor matched multiple sectors. After running the same tool on another disk, Ultima II this time, it returned many identical matches with the first run. I knew i was on the right track(pun intended) and it looked like the layout was same for all disks.
With the result from the checksum runs on a couple of more disks I (roughly) knew the following:
File 1: Tracks 01-08
File 2: Tracks 09-16
File 3: Tracks 17-25
File 4: Tracks 26-35
The sectorlayout was not the same throughout the four files, but I could see a repetitive pattern which filled in some of the blanks after tweaking my tool a bit.
With the tables generated, and with the information in them, I wrote out the files to diskimages. Now I had 9 disks, with partially written data to them. I tried loading some files, but they often halted in the middle of loading since it hit an empty(zero-filled) sector telling the drive it is the last sector to load. There is no data written on those sectors either.
This is where I got ideas for another tool, and where I searched for partial matches from other releases found on CSDB. One disk was Summer Games and I knew it has a number of files which matches with the data written (and not yet written) to the diskimage.
My new tool would try to extract a file from the images I built. When it hit the track/sector links $00,$00 (i.e. empty sector) it would store the current track/sector and know which sector(and which track) was missing data. I also had pointed out the corresponding (complete) file and the tool searched/compared where identical data ended. From that offset it matched ($0100-2) of data from the four files which had not yet been written to disk.
When the data was identical, I got a visual feedback to confirm if the (next) track/sector link was within reasonable limits. I was able to verify it with the earlier information about which files held which tracks and if the sector links follows the pattern how a file gets written to disk (i.e. 01,11,02,12,03,13,04,14…).
With a couple more files from other games, and with my tool, I was able to reconstruct all track/sector data for all the 9 disks :).
However, we still don’t know which tool was used for this backup, if you have any information, please let me know.
20/03-2016 Sailor of Triad (edited and republished 5/6-2017 Xiny6581)